TinyTextMinerとRによる、はじめてのデータマイニング
づや会 vol5 ~機械学習の話~登壇時の資料です。LIGブログの記事を元にテキストマイニングしてみました。
スライド
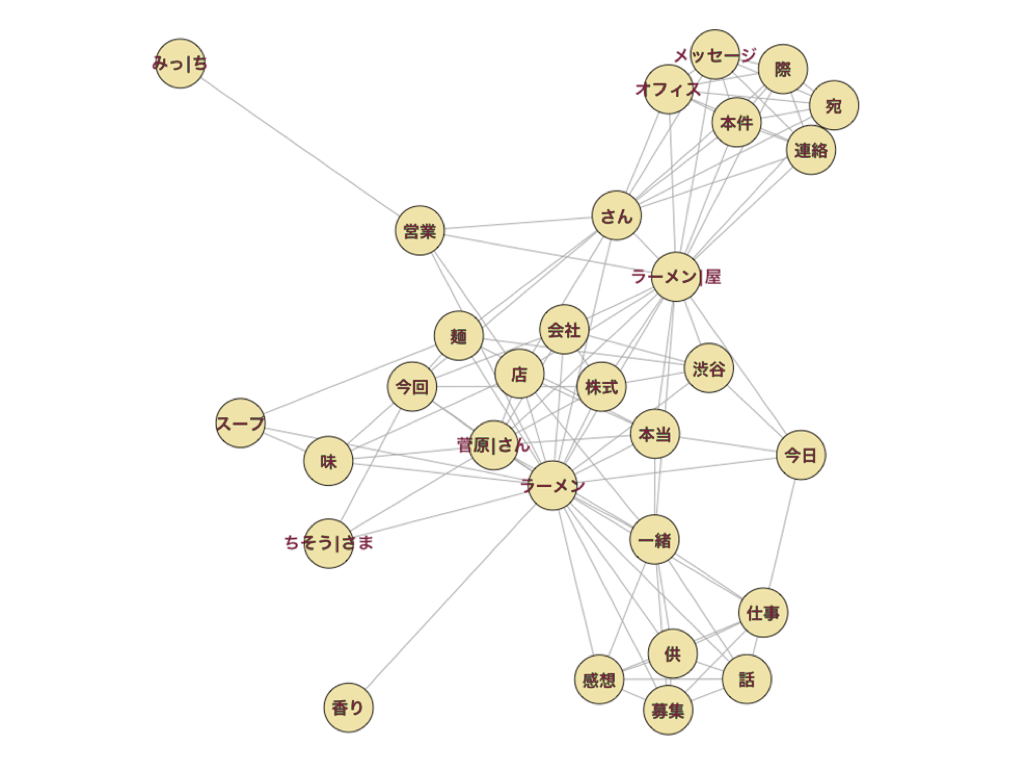
LIGブログのいくつかのメンバーの記事を対象に、TinyTextMinerとR言語を使って頻出単語の無向ネットワーク分析グラフを作成しました。
やっていることはほとんど「テキストマイニングツール TTM (TinyTextMiner) の理念と使い方」と同じ内容です。
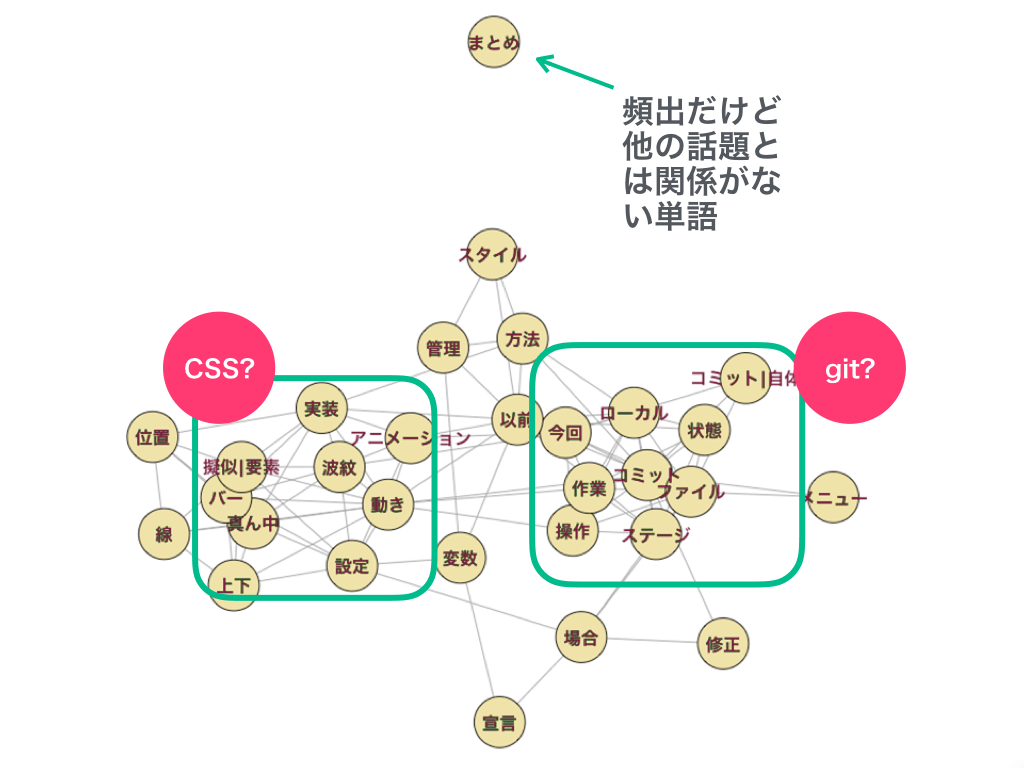
また、スライド31ページ目の「意味のない単語は辞書を鍛えてフィルタリングする必要がありそう」という内容について、づや会参加者のScenesK様から以下のコメントをいただきました。
テキストマイニング(ほりでーさん)に関して。以前、ニュース記事をベクトル化してコサイン類似度から類似記事を見つけるということをやったのですが、その際TF-IDF(https://ja.wikipedia.org/wiki/Tf-idf) という指標を用いました。このTF-IDFかIDFのみを使えば、あまり意味のない単語を自動で除外できるのではないかと思います。あと、word2vecというのを使って単語をベクトル化すると、単語同士の距離から似ている単語をまとめられるかもしれません。こちらはやったことないので推測です。以上、参考まで f^_^;
意味のない一般形な単語を自動でフィルタリングできる指標があるようですね。有益な情報をありがとうございます! (私にはまだ使いこなせなさそうですが……)
参考リンク
- R言語: R: The R Project for Statistical Computing
- RStudio(R言語のIDE): RStudio – Open source and enterprise-ready professional software for R
- TTM: TTM: TinyTextMiner β version
- TTMのチュートリアル: テキストマイニングツール TTM (TinyTextMiner) の理念と使い方
Rサンプルコード
CSVからネットワーク分析グラフを出力するコード
ほとんど「テキストマイニングツール TTM (TinyTextMiner) の理念と使い方」と同じ内容です。
# igraphパッケージをあらかじめインストールしておく
library(igraph)
# エクセルで保存したCSVファイルを想定したエンコーディングです
sna <- read.csv("target_ttm5.csv", header=T, row.names=1, fileEncoding="CP932")
sna <- as.matrix(sna[1:30,1:30])
diag(sna) <- 0
sna[sna>=1] <- 1
sna.g <- graph.adjacency(sna, mode="undirected")
V(sna.g)$names <- rownames(sna)
# グラフ描画
plot(sna.g, vertex.label=V(sna.g)$names, layout=layout.fruchterman.reingold)
.Rprofile
~/.Rprofileとして保存してRStudioを再起動すると日本語グラフが文字化けしないで作れるようになります。
setHook(packageEvent("grDevices", "onLoad"),function(...) grDevices::pdf.options(family="Japan1"))
setHook(packageEvent("grDevices", "onLoad"),function(...) grDevices::ps.options(family="Japan1"))
setHook(packageEvent("grDevices", "onLoad"),
function(...){
# 本当はセリフ書体が入るが、見た目の好みでサンセリフ体 grDevices::quartzFonts(serif=grDevices::quartzFont(
c("Hiragino Kaku Gothic Pro W6",
"Hiragino Kaku Gothic Pro W6",
"Hiragino Kaku Gothic Pro W6",
"Hiragino Kaku Gothic Pro W6")))
grDevices::quartzFonts(sans=grDevices::quartzFont(
c("Hiragino Kaku Gothic Pro W6",
"Hiragino Kaku Gothic Pro W6",
"Hiragino Kaku Gothic Pro W6",
"Hiragino Kaku Gothic Pro W6")))
}
)
attach(NULL, name = "MacJapanEnv")
assign("familyset_hook",
function() { if(names(dev.cur())=="quartz") par(family="serif")},
pos="MacJapanEnv")
setHook("plot.new", get("familyset_hook", pos="MacJapanEnv"))
文字化け問題で参考にしたサイト
- R - 事始め
- Rとウェブ解析:MACでグラフの日本語文字化けを防ぐ簡単な方法
- 不正なマルチバイト文字に七転八倒した。 - R七転八倒
- png/jpgなどにplotする際に適切に日本語文字列を描画する - Qiita
- mac OS版 Rのplotで日本語表示をしてみた|刻苦勉励 - share my ideas and experiences -
- 須通り_統計_Rにおける作図時のフォント設定を極める
コメント
テーマが機械学習ということもあり、今までで一番ネタ探しが難しいづや会でした。ほんとうはDeepDreamをいじってみたかったのですが、Python(の依存管理)が難しすぎて断念。代わりに以前から興味のあったテキストマイニングに挑戦してみました。
ちなみに、たまたま最近読んだ社会学系の論文では、Twitterのテキストマイニングから仮説を検証していて驚きました。既に色々な分野で活用されている技術なのですね!
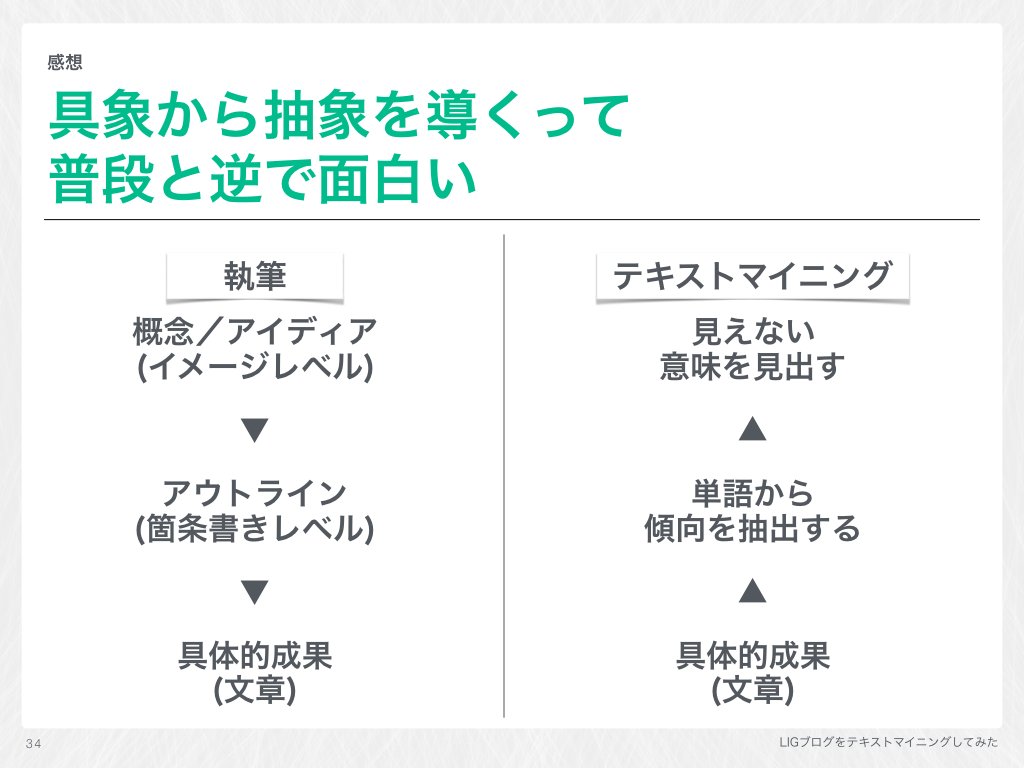
スライド(一部)



※投稿内容は私個人の意見であり、所属企業・部門見解を代表するものではありません。